Strap In for a Cosmic Code Dive: Building and Navigating OpenAI's Lunar Lander Model


Table of contents
- What is <mark>Reinforcement Learning</mark>
- Setting Up the Space Stage
- Know Your Surroundings
- Dance Moves in Space
- Cheers and Jeers - The Rewards
- 1. Requirements for a Galactic Expedition
- 2. Constructing the Celestial Simulator
- 3. Setting the Galactic Guidelines
- 4. Constructing the Reinforcement Learning Framework
- 5. Training the Interstellar Navigator
- 6. Testing the Galactic Navigator
- Conclusion: Touchdown! The Code Chronicles
- Biblios:
- Some clips from our training:

Greetings, code aficionados and interstellar architects! 🚀
Today, we embark on an odyssey through the intricacies of OpenAI's Lunar Lander Model, unravelling the professional nuances of constructing and navigating this remarkable piece of artificial intelligence. So, tighten your seatbelts—this is not your typical spacewalk through code.
What is Reinforcement Learning
Reinforcement learning is like the rockstar of artificial intelligence (AI) discussions—it's super popular because it can totally change how businesses operate.
Imagine a toddler learning to walk. When they take a step and everything goes well, they feel good about it and keep doing it. But if they stumble, they adjust their steps. This is a bit like how machines learn through reinforcement learning.
In the AI world, we use reinforcement learning to teach machines and software agents the best actions to take. It's like guiding them to make the right moves by giving them a thumbs up (positive reward) when they do something good. Just as toddlers learn from their experiences, machines learn from the outcomes of their actions in the environment. So, reinforcement learning is basically a cool way machines can learn and get better at what they do. 🚀🤖
Setting Up the Space Stage
First things first, we need to set up our 'Lunar Lander' environment. The OpenAI Gym GitHub page [1] and documentation link [2] provide a step-by-step guide.
Picture it like setting the stage for a play.
Know Your Surroundings
Now, let's talk about the environment itself. The 'state' is like taking a snapshot of the current situation. In this lunar realm, there are 8 different things we're keeping an eye on. It's a bit like noting down the temperature, wind speed, and other details before you make a decision.
Dance Moves in Space
Our agent, the spacecraft, has some slick 'action' moves. It can choose from four different actions: 'do_nothing' (chilling in space), 'fire_left_engine' (a left-side boost), 'fire_right_engine' (going right), and 'fire_main_engine' (full throttle!). Think of it as choosing the right dance move for the cosmic ballet.
Cheers and Jeers - The Rewards
Now, why would our agent bother with all these moves? Well, every time it pulls off a maneuver, it gets a little reward, but it's a negative one. This might sound odd, but it's like giving a small penalty to encourage the spacecraft to land smoothly and quickly. If it messes up and crashes or just decides to take a nap, the game is over, and it gets either a big -100 or +100 points, depending on the outcome. It's a bit like saying, "Good job, here's a high five!" or "Oops, better luck next time!"
1. Requirements for a Galactic Expedition
Before we lift off, let's gather our cosmic toolkit. Ensure you have:
Python: The chosen language for this cosmic endeavor.
OpenAI Gym: The training ground for our Lunar Lander.
NumPy: To handle the mathematical computations orbiting our model.
2. Constructing the Celestial Simulator
In the realm of Lunar Lander, the environment is everything. Construct a celestial simulator using OpenAI Gym, defining the observation space, action space, and reward system. Your Lunar Lander needs eyes (observations), limbs (actions), and a scoring system to navigate the cosmos.
import gym
Create the Lunar Lander environment
env = gym.make('LunarLander-v2')
3. Setting the Galactic Guidelines
Define the parameters for your Lunar Lander. Establish guidelines for exploration, such as the number of episodes and maximum steps per episode. This helps set the stage for controlled experimentation.
num_episodes = 1000
max_steps_per_episode = 1000
4. Constructing the Reinforcement Learning Framework
Implement the core of your Lunar Lander model using Reinforcement Learning. This involves creating a neural network that can learn from observations and take actions accordingly.
import tensorflow as tf
from tensorflow.keras
import layers
# Define the model
model = tf.keras.Sequential([ layers.Dense(128, activation='relu', input_shape=(env.observation_space.shape[0],)), layers.Dense(64, activation='relu'), layers.Dense(env.action_space.n, activation='linear') ])
# Compile the model
model.compile(optimizer=tf.optimizers.Adam(learning_rate=0.001), loss='mse')
5. Training the Interstellar Navigator
Train your Lunar Lander model using the data generated from its interactions with the environment. This involves running episodes, collecting data, and optimizing the model to maximize rewards.
for episode in range(num_episodes):
state = env.reset()
episode_reward = 0
for step in range(max_steps_per_episode):
# Choose action using the model's policy
action = model.predict(state.reshape(1, -1))
# Take the chosen action and observe the next state and reward
next_state, reward, done, _ = env.step(action.argmax())
# Update the model using the observed data
model.fit(state.reshape(1, -1), action, verbose=0)
state = next_state
episode_reward += reward
if done:
break
print(f"Episode {episode + 1}/{num_episodes}, Total Reward: {episode_reward}")
6. Testing the Galactic Navigator
Once trained, test the Lunar Lander model on unseen environments to evaluate its performance. This step ensures that your AI navigator can gracefully handle various lunar scenarios.
test_episodes = 10
for episode in range(test_episodes):
state = env.reset()
episode_reward = 0
for step in range(max_steps_per_episode):
action = model.predict(state.reshape(1, -1))
next_state, reward, done, _ = env.step(action.argmax())
state = next_state
episode_reward += reward
if done:
break
print(f"Test Episode {episode + 1}/{test_episodes}, Total Reward: {episode_reward}")
Conclusion: Touchdown! The Code Chronicles
Congratulations, intrepid coders! You've successfully navigated the cosmos, building and training your Lunar Lander Model. From defining the celestial playground to orchestrating the symphony of neural networks, each step propels us further into the future of artificial intelligence and space exploration. So, let the code chronicles continue, and may your algorithms touch down on new frontiers! 🌌✨
Biblios:
Brockman, G., Cheung, V., Pettersson, L., Schneider, J., Schulman, J., Tang, W., & Zaremba, W. (2016). OpenAI Gym. arXiv preprint arXiv:1606.01540.
Silver, D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., Van Den Driessche, G., ... & Hassabis, D. (2016). Mastering the game of Go with deep neural networks and tree search. Nature, 529(7587), 484-489.
Sutton, R. S., & Barto, A. G. (2018). Reinforcement Learning: An Introduction. MIT Press.
OpenAI Gym Documentation - Lunar Lander Environment.
DeepLizard's Reinforcement Learning Series on YouTube.
Some clips from our training:
Model yet to learn how to land (Initial Stages)
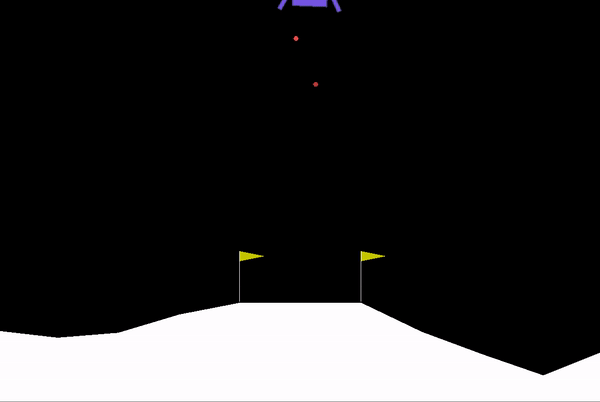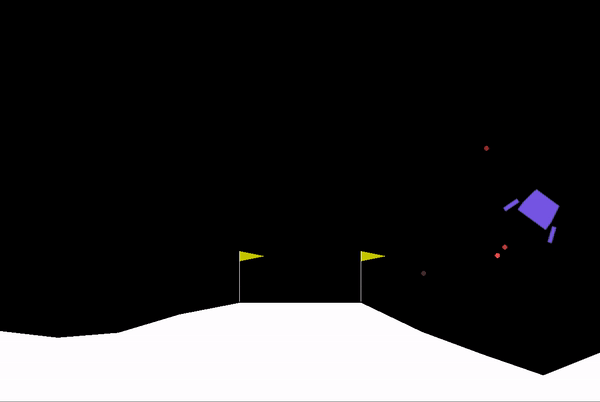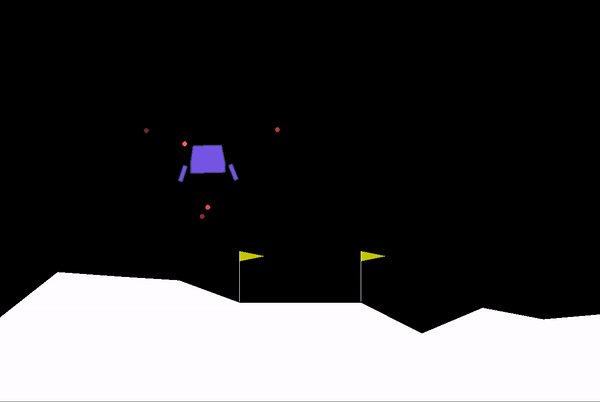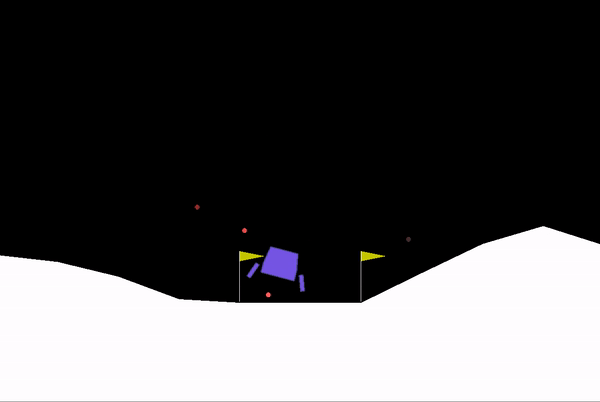
Model slowly learning its way to make a safe learning (Mid-Stage)

The model has learned its way to a safe and sound landing!!! (Final Stage)
